Компонентное программное обеспечение, ч. 3
© 1997, Cuno Pfister (Oberon Microsystems, Inc.)
© 2005, русский перевод: Ермаков И.Е.
Для публикации текста требуется письменное разрешение автора и переводчика.
3 Требования к компонентному ПО
Идея компонентного ПО настолько очевидна, что можно только удивляться, почему она не появилась раньше. Чтобы ответить на этот вопрос и дать начальные технические сведения о том, что есть компонентное ПО, мы сначала посмотрим на его предысторию. Мы увидим, что важной причиной позднего прихода к общему компонентному ПО было отсутствие подходящей стандартизированной инфраструктуры.
3.1 Операционные системы
В первые дни компьютеров прикладная программа имела полный контроль над компьютером. Приложения могли свободно использовать все аппаратные ресурсы, так как в одно и то же время на одной машине работала только одна программа. Однако, это также означало, что программа реализовывала с нуля все функции ввода-вывода.
Позднее основные полезные службы были собраны вместе в специальной программе, которая была постоянно доступна, — это так называемая операционная система. Прикладная программа теперь уже не имела полного контроля над машиной, она обращалась к операционной системе и использовала ее функции, когда это было возможно. Однако, такая потеря контроля над машиной более чем компенсировалась ростом продуктивности, которая стала следствием многократного использования служб операционной системы.
Операционную систему можно считать программным компонентом, который многократно используется всеми приложениями, написанными под нее. С другой стороны, приложение можно считать программным компонентом, который динамически расширяет функциональность операционной системы. Разделение программного обеспечения на операционные системы и прикладные программы можно рассматривать как первый чрезвычайно успешный пример компонентного ПО.
Десятилетия назад компьютеры были очень дорогими. Поэтому было неприемлемым, чтобы одна-единственная программа блокировала своим выполнением целый компьютер. В частности, интерактивное приложение большую часть времени просто ждет ввода пользователя с терминала. В этой связи было изобретено разделение времени, то есть, ОС теперь позволяли выполняться нескольким приложениям одновременно, выдавая каждому из них короткий квант времени, а затем передавая управление следующему. Так как компьютеры стали довольно быстрыми, пользователи могли не обращать внимания на то, что их компьютер работает на каждого из них только часть общего времени.
Это было большим шагом вперед — дать доступ к компьютерам большему числу людей. Но это также создавало проблемы. Программы не должны были мешать друг другу. В частности, нельзя было допустить, чтобы одна программа изменяла память (и тем самым — состояние) другой программы. Конечно, программа с правильным поведением не должна этого делать. Но как быть с неправильными программами? Даже в те времена было ясно, что очень мало программ свободны от ошибок и защищены от неверного поведения. Таким образом, безопасность стала важной проблемой.
Проблема была решена введением аппаратных механизмов защиты. Аппаратная защита могла элегантно комбинироваться с поддержкой гибкой системы управления памятью, так называемой виртуальной памятью. В общих чертах, каждая программа представляет, что она имеет доступ целиком ко всей памяти компьютера, и эта память отделена от памяти, которую используют остальные программы. Эти раздельные адресные пространства предотвращают любые прямые взаимовлияния прикладных программ. Программа может напрямую взаимодействовать только с операционной системой, через специальные системные вызовы. Современные микропроцессоры обеспечивают специальную поддержку для таких вызовов.
К сожалению, аппаратная защита работает слишком хорошо. Это предотвращает взаимовлияния, но также предотвращает и интеграцию. В этом - одна из причин, почему компонентное ПО не могло бы развиваться на такой основе. Тесная интеграция необходима компонентному ПО для работы! Оценивающий алгоритм должен иметь прямой доступ к тому балансовому отчету, который он оценивает. В то же время, операционные системы вводят функции, которые обеспечивают некоторый уровень интеграции приложений. Это, например, трубы или стандартные библиотеки. Однако эти механизмы слишком ограничены и неэффективны. Они не предоставляют необходимой основы для компоненциализации операционных систем и приложений, и потому не смогли остановить тенденции «жирного» ПО. Единственная область, в которой старые операционные системы удачно вводили многократно используемые компоненты, — это драйверы устройств. В этой сфере накоплен изрядный опыт изоляции друг от друга тесно связанных компонентов, то есть, драйверов устройств, приложений и операционной системы. Этот делается достаточно эффективно и позволяет развивать все эти компоненты до некоторой степени независимо.
Чтобы создавать приложения, разработчики должны знать, какие службы предоставляются операционной системой. Им необязательно знать, как эти службы реализованы. В этих целях создаются абстрактные описания интерфейсов операционной системы. Чтобы сделать приложения переносимыми и, следовательно, открыть для них наибольший рынок, интерфейс операционной системы должен быть одинаково независимым как от ее реализации, так и от аппаратной конфигурации. Операционная система MS DOS показала, насколько упешным может быть строгое соблюдение стандарта, в то время как Unix показала, какими фатальными могут становиться даже легкие от него отклонения. Пользователи компонентов хотят получать коробочное ПО, которое работает в стиле «plug-and-play», а не разбираться с набором несовместимых двоичных форматов.
Чтобы написать приложение, недостаточно знать, какие функции предоставляет операционная система. Чтобы создавать реальный код, разработчик — или по крайней мере автор компилятора — должен знать все нюансы вплоть до каждого бита и каждой инструкции, как должен делаться вызов и передаваться параметры; то есть, должны существовать стандартные соглашения по вызову процедур. К настоящему времени были опробованы различные соглашения вызовов. Некоторые операционные системы даже требуют использования нескольких типов вызовов, например, Mac OS использует пол-дюжины различных соглашений. Однако большинство соглашений по вызову сильно ограничены. Например, если процессор поддерживает несколько тысяч различных системных вызовов, на практике эти вызовы могут использоваться лишь для обращений к ОС из приложений — и даже нужды самой ОС могут превзойти ограничения процессора. Только более современные соглашения вызовов могут быть обобщены для произвольного числа независимо разработанных компонентов, включая (но не ограничиваясь) операционной системой.
Операционная система должна иметь возможность загружать и запускать приложения динамически, во время выполнения. Это требует стандартного формата для файлов с кодом приложений, чтобы загрузчик операционной системы мог с ними работать. Подобно соглашениям вызовов, такие форматы файлов (например, формат Windows EXE) оказались слишком ограниченными, и были созданы новые форматы, более подходящие для компонентного ПО (например, формат Windows DLL).
Обобщая наиболее важные моменты, которые мы можем почерпнуть из операционных систем, приведем следующий список того, что требуется для компонентного ПО:
- стандарт, который допускает динамическую загрузку компонентов (динамически загружаемые библиотеки, соглашения вызовов)
- стандартный программный интерфейс (например, интерфейс ядра Unix)
- механизм защиты, который предотвращает нелегальные изменения состояний одних компонентов другими
- способ разделения данных между компонентами без их копирования взад-вперед и без явных преобразований в линейные потоки байт
Мы вновь встретимся с этими моментами и обсудим их более детально в следующих разделах.
3.2 Интерфейсы как контракты
Компонент — это черный ящик, который взаимодействует со своим окружением только через свой интерфейс. Интерфейс определяет стандарт, которому производители компонентов обязаны следовать и которого пользователи вправе ожидать. Если интерфейс опубликован, то многие производители и пользователи могут следовать ему, и следовательно, вокруг него может развиваться рынок. Мы можем смотреть на интерфейс компонента на бинарном уровне, на уровне приложений конкретной отрасли, и иногда на уровне пользовательского интерфейса. Но перед тем, как смотреть на существующие стандарты с таких различных уровней, нам следует взглянуть ближе на то, что такое интерфейс.
Интерфейс определяет, что должен предоставить производитель компонента, и что заказчик ожидает получить. Например, математический компонент может реализовать интерфейс, который определяет процедуры для вычисления функций синуса и косинуса:
DEFINITION Math; PROCEDURE Sin (x: REAL): REAL; (* возвращает синус x *) PROCEDURE Cos (x: REAL): REAL; (* возвращает косинус x *) END Math.
Как подметил Бертран Мейер [Meyer89], интерфейс можно сравнить с контрактом. В этом разделе мы покажем, как многие аспекты настоящих контрактов можно применить к интерфейсам компонентов. Контракты содержат, как минимум, две части, то есть, поставщика, который обещает предоставить некоторый товар, и заказчика, который обещает приобрести товар соответствующим образом. Например, писатель пишет книгу, а издатель ее публикует. Писатель и издатель связаны условиями контракта.
Иногда контракты исходят от третьей стороны. Например, многие профессиональные организации имеют стандартизированные контракты для своей деятельности.
Контракты бывают плохими и хорошими. Хороший контракт должен быть ясным, полным и кратким. Плохой контракт неоднозначен, опускает важные моменты и содержит несущественные детали. Все эти нарушения ведут к тому, что одна сторона получает ложное представление о поведении другой:
- Если в контракте присутствуют неоднозначности, каждая сторона может предъявить свою трактовку того, что она и другие стороны обязаны делать. Это сразу ведет к несовместимым предположениям, и затем — к конфликту.
- Если опущено нечто важное, могут всплыть неявные предположения. Если такое предположение остается истинным некоторое время, оно может превратиться в неписанный закон, то есть, в подразумеваемое ограничение контракта. Но это ограничение является хрупким, так как сделанные допущения может перестать поддерживать другая сторона, если она найдет причины поступать в будущем иным образом. Это приводит к сильной борьбе или даже анулированию контракта.
- Если в контракте фиксируются незначительные детали, то на обе стороны ложатся ненужные ограничения. Придет время, когда одна из сторон захочет изменить контракт, чтобы условия стали более гибкими. Это может привести к дорогим и, возможно, безуспешным попыткам их согласовать. Или, вместо повторного согласования, контрагент может просто нарушить контракт. Становится вероятным либо анулирование контракта, либо судебная тяжба.
В общем, неоднозначные или неполные контракты - хрупкие, в то время, как перегруженные контракты слишком стеснительны. И те, и другие, вероятно, приведут к конфликтам. Интересно, что конфликты часто происходят, когда по какой-либо причине контракт приходится корректировать. Это очень важный эффект, как мы позднее увидим. Большое искусство — составлять контракты, которые и достаточно полны, и не перегружены.
Контракты имеют и другие интересные качества. Например, если некто обязан предоставить некоторое количество ценного товара, то получатель не будет жаловаться, если получит больше. И обратно: если получатель в течение некоторого времени требует меньшее количество, чем было согласовано, поставщик обычно также не возражает. Это означает, что в некоторых случаях нарушения контрактов безвредны. Другой интересный момент — контракты часто имеют дату истечения, то есть, они действительны только на протяжении определенного периода времени.
Как все это относится к интерфейсам между компонентами? Стороны заключают контракт, соответствующий взаимодействию компонентов через некоторый интерфейс. Плохие контракты неясны, неполны и перегружены.
Неясный контракт соответствует неясной спецификации интерфейса. К сожалению, это скорее правило, чем исключение. В то время как синтаксис интерфейса может быть задан очень легко, ясная семантика трудноуловима. Обычно имеется простой неформальный текст, который описывает, что из себя представляет некоторый интерфейс. Формальные и полуформальные методы специфицирования могут помочь сделать интерфейсы менее противоречивыми. Например, процедура может описываться предусловиями и постусловиями, то есть, какие условия должны выполняться на входах процедуры, когда она вызывается, и какие условия должны быть сформированы на выходе вызванной процедурой. Это — довольно долгий путь к менее противоречивым интерфейсам, однако, он все еще не описывает все важные аспекты, например, быстродействие.
Приведем пример следующей формальной спецификации:
PROCEDURE Sum (x, y: INTEGER; OUT z: INTEGER) Предусловие: (x <= 0) & (y <= 0) Постусловие: z = x + y
Предусловие говорит о том, что входные параметры x и y должны быть неотрицательными. В постусловии оговаривается, что выходной параметр z содержит сумму x и y.
Это интерфейс (контракт) между тем, кто реализует процедуру, и тем, кто ее вызывает. Реализующий волен допустить менее строгие предусловия, например, он может также позволить отрицательные значения для x и y. Однако никто не может предполагать, что эти значения обрабатываются верным образом. Точно так же, реализующий может обеспечить более строгие постусловия, то есть, он может предоставить больше, чем от него ожидают.
А вот пример верной реализации для приведенной спецификации:
PROCEDURE MySum (x, y: INTEGER; OUT z: INTEGER); BEGIN z := ABS(x) + ABS(y) END MySum;
Как часто бывает, реализация использует более слабое предусловие (допускаются также отрицательные числа) и усиленное постусловие (вычисляется сумма абсолютных значений), чем это требует спецификация.
Интерфейс, который задает слишком много несущественных деталей, заставит программистов использовать их и допускать их истинность. Становится невозможным изменить эти детали позже, даже если это действительно потребуется. Особенно заманчиво приводить много деталей, когда уже существует сложный и недокументированный код, который должен быть включен в компонент. Тогда простым решением кажется опубликовать исходный код и не беспокоиться по поводу определения менее ограниченного интерфейса. В результате вся реализация становится интерфейсом, и ее уже никогда нельзя изменить, так как это может нарушить работу клиентского кода.
Использование полной реализации в качестве спецификации создает также проблему сложности: очень тяжело анализировать десятки тысяч строк кода, чтобы понять, как себя ведет фрагмент программы. Такая сложная «спецификация» подобна контракту, который включает в себя книгу, написанную мелким шрифтом.
Даже если программный компонент имеет минимальный и хорошо определенный интерфейс и исходный код недоступен, изобретательный программист изучит методом проб и ошибок особенности поведения компонента, которые не зафиксированы в интерфейсе. В общем, такой программист получает свою дополнительную спецификацию интерфейса, которая объемнее, чем опубликованный интерфейс, то есть, контракт. Даже если он получит преимущества от такого более полезного, но хрупкого расширенного интерфейса, то его код может перестать работать, когда выйдет новая версия компонента, внутреннее поведение которой изменилось. Всем нам знаком этот эффект по приложениям, которые вдруг перестают работать правильно после установки новой версии операционной системы. Эти приложения опираются на предположения, которые не были внесены в контракт и потому не гарантируются. Конечно, если достаточное количество важных приложений полагается на эти недокументированные возможности, производитель операционной системы может оказаться вынужденным не менять их в будущем никаким образом. Таким образом он вынужденно принимает установившиеся требования рынка.
Проблема дополнительных спецификаций, полученных методом проб и ошибок, и хрупкость, происходящая от них, не могут быть решены полностью. Но, как мы увидим далее, в языках программирования есть популярные конструкции, которые увеличивают шансы попасть в такую ловушку. Поэтому они должны быть исключены из компонентных интерфейсов.
Могут ли контракты-интерфейсы соблюдаться? До некоторой степени это соблюдение возможно. Некоторые нарушения контракта могут быть обнаружены при компиляции компилятором, другие обнаруживаются позднее во время выполнения, с применением соответствующих аппаратных и программных механизмов защиты.
На самом простом уровне, каждому компоненту нужно взаимодействовать с другими компонентами исключительно через их интерфейсы; это разновидность контракта, иначе говоря, закон для программиста. Например, прямая запись в память другого компонента будет грубым нарушением закона. В закрытой системе, то есть, в изолированном монолитном приложении, эта проблема решается легко. Но в открытых компонентных системах взаимовлияния компонентов — это принципиально более важный вопрос. Если аппаратная и программная инфраструктура может полностью предотвратить нарушение соглашений, надежность системы возрастет, так как возможности компонента что-либо разрушить будут ограничены. Существующие средства аппаратной защиты и некоторые современные языки программирования спроектированы так, чтобы обеспечить безопасность такого рода.
Когда компонент продается по всему миру, производитель обычно не знает ничего о своих пользователях. Это значит, что в контракте большинство сторон неизвестны. Контракты могут изменяться только с согласия всех сторон, следовательно, интерфейс таких компонентов больше никогда не может измениться. За исключением безопасных изменений, описанных выше, то есть, больших гарантий или меньших требований, сохраняется оригинальная спецификация интерфейса.
В принципе, отвергнуть интерфейс, то есть, отменить контракт, можно, если истек срок времени, указанный в интерфейсе. На сегодняшний день это бесполезно. Рынок развивается настолько быстро и, следовательно, ПО так же быстро устаревает, что временные ограничения на интерфейсы не кажутся существенными. Но кто знает — это может измениться в будущем.
И, наконец, если поставщик и заказчик соглашаются использовать стандартный контракт, составленный отдельной организацией, специализирующейся на контрактах, точно также разработчик и сборщик компонентов могут согласиться на стандартный интерфейс компонента, который может быть определен некоторой третьей стороной — разработчиком каркасов. Построение каркасов детально обсуждается в 4.2.
Мы увидели, что контракты имеют глубинные связи с природой интерфейсов компонентов. Но сейчас мы должны обратить внимание на проблему хорошей спецификации интерфейсов. Неясные интерфейсы ведут к несовместимостям, неполные интерфейсы ведут к получению дополнений к ним методом проб и ошибок, а перегруженные интерфейсы ведут к чрезмерно ограниченным или неправильным реализациям. Недоопределение и переопределение одинаковым образом ведут к конфликту: когда компонент заменяется новой версией, зависящие от него компоненты могут внезапно перестать работать.
3.3 Объектные модели
Объектная модель определяет необходимые правила совместимости компонентов на уровне двоичного кода, так что компоненты могут взаимодействовать на конкретной машине, даже если они разрабатывались независимо. Чтобы достичь этой цели, объектная модель должна стандартизировать следующие аспекты:
- язык определения интерфейсов (IDL, interface definition language)
- механизм для запроса интерфейсов и их атрибутов, то есть, «репозиторий интерфейсов»
- формат кодовых файлов для хранения двоичного кода, который может быть загружен во время выполнения, то есть, формат динамически компонуемых библиотек
- механизм для загрузки соответствующих кодовых файлов для данного интерфейса, то есть, «репозиторий реализации»
- механизм для загрузки кодовых файлов в память, то есть, компонующий загрузчик
- механизм для проверки версий загружаемого кода
- механизм для создания экземпляров загруженного класса, то есть, для размещения объектов
- соглашения по вызову методов объекта
- механизм для навигации между полиморфными типами объекта
- механизм для возврата неиспользуемой памяти, то есть, уничтожения объектов
- формат сообщений, если поддерживаются распределенные объекты
В следующих абзацах мы обсудим эти моменты по порядку.
1) Компонент может пользоваться услугами другого компонента. Для этого разработчику надо всего лишь знать интерфейс используемого компонента. Возможно, для этого интерфейса пока еще даже нет реальной реализации. Интерфейс должен быть некоторым образом описан. Текстовое описание интерфейса записывается на языке описания интерфейса (IDL, interface description language). В идеале, он должен быть подмножеством того языка, который использует разработчик. Однако в целом объектная модель независима от языка, и конечно же, IDL может быть подмножеством только лишь очень похожих языков программирования. Другие языки будут применимы в большей или меньшей степени — от несовпадения до полного несоответствия, то есть, потребуется перевод конструкций описания. Например, IDL позволяет задавать беззнаковые целые, но такие языки как Java или Компонентный Паскаль поддерживают только знаковые целые. Это требует отображения, например, во вспомогательные типы данных, определенные в библиотеках. Такой подход может вести к большим сложностям.
2) IDL-описание предоставляет разработчику информацию об интерфейсе объекта. Если возможно, компилятор должен использовать такую информацию для проверки того, корректно ли используется интерфейс. В этих целях часто существует двоичный формат для описание интерфейсов, в дополнение к текстовому IDL-формату. Доступный набор таких двоичных описаний называется репозиторием интерфейсов. Он может состоять просто из набора так называемых символьных файлов, или он может храниться в базе данных какого-либо рода.
3) Когда компонент компилируется, компилятор должен создать файл, который содержит сгенерированный код. Формат такого файла должен подходить для загрузки во время выполнения, то есть, он должен быть динамически загружаемой библиотекой. Часто используется формат DLL операционной системы. Для объектных моделей, привязанных к языку, вместо этого можно использовать более эффективный формат облегченных DLL.
4, 5) Во время выполнения, когда компоненту первый раз потребовались услуги другого компонента, тот компонент загружается. Загрузчик сначала находит кодовый файл для компонента. Расположение кодового файла может быть очевидным, например, имя компонента может напрямую определять путь к его кодовому файлу в файловой системе. Другой вариант - текущее положение кодового файла может запрашиваться из конфигурационной базы данных. Косвенный подход более гибок, но более требователен в плане системного администрирования. Набор кодовых файлов или соответствующая база данных называются репозиторием реализации.
Было предложено разработать даже еще более гибкие методы для поиска подходящей реализации компонента с данным интерфейсом, использующие расширенные критерии поиска. Насколько эти так называемые «службы-маклеры» (trader services) будут успешными, мы увидим в дальнейшем.
6) Когда загрузчик успешно нашел компонент и загрузил его код в память, он может проверить, действительно ли загруженный код реализует запрошенный интерфейс, и совместимы ли версии загруженного компонента и его клиента. Такая проверка — насущная необходимость, поскольку нельзя допустить, чтобы кофликт версий привел некоторое время спустя к краху, и при этом пользователь мог бы только догадываться о причине проблемы. Некоторые объектные модели не предоставляют адекватного механизма контроля версий и перекладывают бремя проверки соответствия частично и полностью на клиентский компонент.
7) Как только код компонента загружен и проверен, могут быть созданы экземпляры его классов. Для этих целей объектная модель должна обладать механизмом размещения объектов. Некоторые объектные модели предлагают косвенный подход к размещению, чтобы дать дополнительную гибкость. В частности, объект может создаваться другим объектом, так называемой фабрикой. Объект-фабрика может сам решать, как размещать и как инициализировать объекты.
8) После того, как объект был создан и стал доступен для других, можно вызывать его методы. Вызов метода — это вызов процедуры, который выполняется не напрямую, а через объект, так что различные объекты могут приводить к вызову различного кода. Обычно объект содержит указатель на таблицу указателей на процедуры. Каждый элемент этой таблицы соответствует одному методу объекта. Поэтому вызов метода - всего лишь непрямой вызов процедуры через таблицу методов объекта. Обычно для этих вызовов используются соглашения вызовов базовой операционной системы.
К счастью, это позволяет использовать объектную модель любому языку программированию, который поддерживает соглашения вызовов, которое принято в операционной системе, плюс ссылки на объекты или ссылки на функции («процедурные переменные»), — то есть, практически любой современный язык, независимо от того, объектно-ориентированный он или нет.

Рис. 3-1. Пример объекта в памяти
9) Полиморфизм — одно из главных качеств любой объектно-ориентированной или компонентно-ориентированной системы. Некотрый интерфейс, поддерживаемый объектом, может быть известен во время компиляции. Он называется его статическим типом. Но объект может приобретать дополнительные возможности, то есть, расширять свой интерфейс, во время выполнения. В зависимости от динамического типа объекта эти возможности могут отличаться. Это называется полиморфизмом («много форм»). Объектная модель должна обеспечить средства, с помощью которых можно получить доступ к таким дополнительным возможностям, если и только если они доступны. Объектно-ориентированный язык программирования в этих целях задает языковые конструкции, такие как расширение типа (также извествное как субтипизация или наследование интерфейса), проверки типа или охрана типа (то есть, безопасные преобразования между типами). Объектная модель может предоставлять похожую функциональность. Без полифморфизма система не может быть расширяемой.
10) Если объект больше не используется, то есть, на него больше нет внешних ссылок, он должен быть уничтожен, чтобы освободилась занимаемая им память. В компонентных системах на объект, который компонент предоставляет вовне, ссылаются какие-либо другие объекты, о которых сам объект ничего не знает. Поэтому должны существовать правила, которые указывают, кто и когда должен уничтожить данный объект. Например, это может сделать другой объект, у которого осталась последняя ссылка на данный. Для определения того момента, когда ссылка на объект стала последней, необходим механизм трассировки ссылок, например, счетчик ссылок в каждом объекте, который подсчитывает количество текущих ссылок на него. Когда количество становится равным нулю, память объекта может быть освобождена. Для того, чтобы такие правила работали, критически важно их правильное использование всеми компонентами. В замкнутых приложениях неправильная работа с памятью является самым главным источником ошибок; но вы, по крайней мере, знаете, кто виноват в произошедшем сбое. В открытых компонентных системах один неправильно работающий компонент может привести к краху всю систему, при этом сложно определить виновного производителя. Поэтому управление памятью в компонентной программной среде является принципиально более важным вопросом, чем в монолитном ПО. В идеале правила и механизмы, вводимые объектной моделью, должны быть достаточно простыми, полными и ясными, чтобы их можно было автоматизировать, то есть, освободить разработчика от ручной работы, предоставив автоматический сборщик мусора. Автоматический сборщик мусора в открытых системах - это не роскошь, а необходимость.
11) Объектная модель, которая поддерживает распределенные объекты, должна определять формат сообщений, который описывает потоки байт, порождаемые удаленным вызовом методов. Того, кто вызывает метод, называют клиентом, того, чей метод вызывают, — сервером. По самому общему сценарию серверный объект и клиент выполняются на разных машинах. С точки зрения разработчика клиент может напрямую вызывать методы серверного объекта. В реальности клиент взаимодействует всего лишь с прокси-объектом, который является локальным представителем настоящего объекта, работающего на удаленной серверной машине. В большинстве реализаций прокси-объект, также как и его аналог на стороне сервера, могут генерироваться автоматически из интерфейса объекта. При удаленном вызове методов прокси посылает запрос со входными параметрами на сервер (см. Рис. 3-2). На сервере происходит вызов подлинного метода. Его результаты отправляются обратно ответным сообщением. Как запрос, так и ответ - это линейные потоки байт; они представляют значения входных (запрос) и выходных (ответ) параметров метода. Использование распределенной объектной модели как замены традиционных способов связи может быть при определенных обстоятельствах привлекательным. Здесь нужно заметить, что прозрачная распределенность объектов принципиально требует полного отделения интерфейса от реализации: клиентский объект не может понять, обращается он к настоящему объект или только к его представителю. Интерфейс один и тот же, но реализация принципиально отличается.
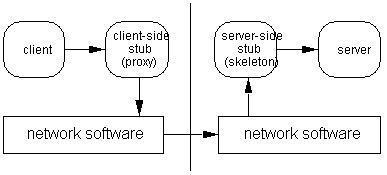
Рис. 3-2. Удаленный вызов методов
Теперь мы увидели все главные составляющие объектной модели. Объектная модель делает возможным подменять один компонент на другой, например на новую версию, без перекомпиляции других компонентов. Это называется двоичной совместимостью версий (release-to-release binary compatible). Например, если вы покупаете новую версию своего любимого текстового процессора, вы вряд ли захотите купить новые версии контроллера орфографии и всех других компонентов, которые работают с текстами. Проблема, которую решает двоичная совместимость версий, также известна как проблема синтаксически хрупкого базового класса.
Использование новой версии компонента не должно вести к сбою только потому, что, например, его таблица методов была перестроена. Все аспекты объектной модели должны быть согласованы таким образом, что сделать возможной двоичную совместимость версий. Решение этой проблемы - первое условие для асинхронного развития компонентов, которое неизбежно на большом рынке.
После этого обзора объектной модели, мы посмотрим на некоторые наиболее важные промышленные стандарты для объектных моделей и на то, как они воплощают те моменты, которые мы обсудили выше.
3.4 Стандарты объектных моделей
IBM System Object Model (SOM) была введена в OS/2 в основном для того, чтобы позволить расширять ОС новыми компонентами; но не столько для того, чтобы разбивать приложения на компоненты. Со временем SOM был расширен до соответствия стандарту CORBA (Common Object Request Broker Architecture). CORBA - это стандарт от Object Management Group (OMG, http://www.omg.org) — консорциума, в который входят сотни компаний. OMG пыталась вводить различные стандарты на распределенные объекты. CORBA стандартизирует общую архитектуру объектной модели, оставляя открытыми все машинно-зависимые («двоичные») аспекты. Совместимость требуется только в двух областях: для исходных кодов приложений и для формата сообщений в сети. На двоичном уровне (например, соглашения вызовов) продукты CORBA вольны использовать полностью различные подходы. Теоретически, этот подход все-таки позволит объектным моделям различных производителей работать вместе.
CORBA предоставляет простой API, который доступен для всех объектов. В добавок к тому, серверные объекты имеют доступ к расширению этого API, к услугам так называемого адаптера объектов. В принципе, могут существовать различные адаптеры объектов; каждый из них оптимизирован для конкретного рода серверных объектов. Обязательный главный объектный адаптер, который единственный широкодоступен, оптимизирован для управления относительно большим количеством легковесных объектов. Это можно объяснить положением многих клиентов CORBA; а именно, больших предприятий, которые заинтересованы в оборачивании объектных интерфейсов вокруг существующих унаследованных приложений. Для большинства реализаций серверных объектов необходимым является доступ к специфичным для продукта расширениям интерфейса базового адаптера объектов. Более того, становится очевидным, что для большего удобства были бы полезны адаптеры объектов, приспособленные к конкретному языку. К сожалению, реализации адаптеров объектов непортируемы, поскольку они должны быть реализованы в терминах не стандартных, а собственных API продукта.
CORBA определяет язык описания интерфейса (IDL), в котором задется синтаксический интерфейс объекта, независимо от языка программирования, используемого для его реализации. Функционально SOM-расширение CORBA IDL является смесью возможностей C++ и Smalltalk. В нем поддерживается множественное наследование и метаклассы, но сохраняются выходные шаблоны (out templates) и сборка мусора. Множественное наследование позволяет комбинировать несколько существующих интерфейсов в одном новом. В противоположность CORBA, которая не поддерживает наследование реализации, SOM поддерживает (множественное) наследование реализации. В противоположность CORBA, SOM также поддерживает нормальные указатели вместо только ссылочных объектов. Обычные исходники на С++, которые используют или реализуют объекты SOM, опираются на специфичные для SOM макросы, которые не совпадают с другими реализациями CORBA и поэтому ограничивают переносимость.
SOM позволяет в новых версиях расширять класс, например, добавляя новые методы, с сохранением совместимости с клиентами старого класса, то есть, проблема синтаксической хрупкости базового класса решена.
CORBA определяет интерфейсы для репозитория интерфейсов и реализаций. CORBA описана сама на себе, то есть, ее интерфейсы могут быть получены из репозитория интерфейса. Эти возможности поддерживаются в SOM.
SOM использует соглашения вызовов и форматы DLL той операционной системы, на которой она реализована. Вызов метода SOM — это вызов процедуры с двумя дополнительными параметрами: один для параметра self (объекта) и один для указателя на окружение (используется, например, для обработки исключений). SOM-объекты предоставляют номера версий (главную и второстепенную), так что клиент может проверить допустимость версии объекта (к сожалению, проверка обычно делается во время загрузки класса, а этого недостаточно — объект может потом быть передан непроверенным некоторому другому объекту, которому требуется другая версия). Есть возможность проверки во время выполнения, является ли объект экземпляром конкретного класса или одного из его подклассов. Распределенная SOM (DSOM) — это CORBA-совместимое расширение SOM, которое добавляет поддержку распределнных объектов.
Будучи в основном похож на CORBA, SOM не накладывает никаких условий на систематическое освобождение памяти, то есть, невозможно разработать сборщик мусора, который будет автоматически освобождать всю неиспользуемую память. Реализация SOM на Apple Mac отличается в этом отношении и предоставляет методы подсчета ссылок в базовом классе SOMObject. К сожалению, это нестандартная модель программирования, которая не может быть положена в основу кросс-платформенного ПО. Например, OpenDoc, который базируется на SOM, предоставляет свою собственную излишнюю схему подсчета ссылок для некоторых своих объектов. С хорошей стороны, Mac SOM значительно более эффективна, чем IBM SOM, и избавлен от проблем утечки памяти.
SOM доступна на нескольких платформах кроме OS/2, например, на AIX, OS/400 и Mac OS. SOM, Orbix (lona), NEO (Sun) и другие реализации CORBA реализуют различные подмножества служб CORBA, коллекция библиотек CORBA варьируется от поддержки перманентных объектов и общих структур данных до транзакций и служб безопасности. Однако эти стандартизированные библиотеки лишь частично реализованы, и большинство производителей предлагают конкурирующие собственные библиотеки, которые более агрессивно распространяются и лучше поддерживаются.
DSOM могла стать первой широко доступной реализацией CORBA, из-за поддержки IBM (OS/2) и Apple (Mac OS), и из-за того, что она стала основой OpenDoc. Этого не случилось. Сейчас надежды сторонников CORBA связаны с Visigenic VisiBroker. Этот продукт лицензирован Netscape, Oracle, Novell, Borland и Sybase. Это вторая и, вероятно, последняя возможность реализации CORBA для широкого рынка, и следовательно, для компонентного ПО, основанного на CORBA.
Microsoft Component Object Model (COM) была разработана для задач интеграции приложений, стала основой для многих служб операционной системы в новых версиях Windows. Язык описания интерфейсов от Microsoft (MIDL) для COM является расширением более старого DCE (Distributed Computing Environment) IDL. DCE является стандартом для удаленного вызова процедур.
Компонент может предоставлять так называемую библиотеку типов, которая является репозиторием интерфейсов. Реестр Windows используется как простой репозиторий реализаций. Для COM используются соглашения вызовов Windows (stdcall). Кодовый файл COM может быть как Windows DLL, для легковесных компонентов, которые загружаются в то же адресное пространство, что и клиент; или Windows EXE, для тяжеловесных компонентов, которые имеют свои собственные адресные пространства (обычно нормальные приложения Windows).
Модель COM отличается от CORBA тем, что объект может предоставлять не обязательно один, а любое количество интерфейсов — на каждый из которых может существовать произвольное количество внешних ссылок. Клиент имеет доступ только к интерфейсам объекта. Следовательно, полностью открытым вопросом остается то, как объект реализован на самом деле: то ли как один объект языка программирования, то ли как составная структура данных. В простейшем случае объект COM предоставляет один интерфейс и реализуется как один длинный блок памяти. Эта ситуация показана на Рис. 3-3. Заметим, что COM является двоичным стандартом, это означает, что структура памяти интерфейса, соглашения вызовов и формат кодовых файлов полностью определены в COM (на самом деле, формат кодового файла определяется не COM как таковым, а Windows и набором инструкций базового процессора).
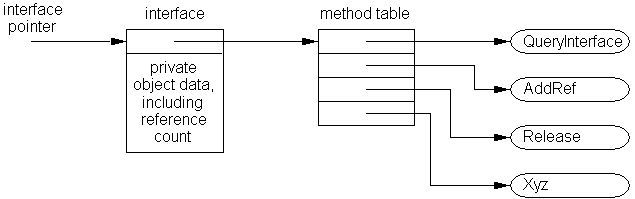
Рис. 3-3. Структура простого объекта COM
Более типична ситуация, изображенная на Рис. 3-4: объект состоит из структуры данных, которая включает множество внутренних (легковесных, не-COM) объектов и нескольких интерфейсов. На эти интерфейсы можно ссылаться из других COM-объектов.
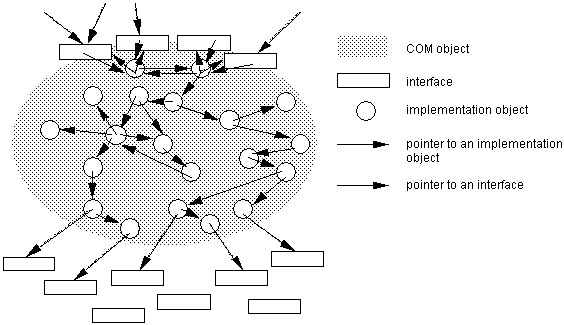
Рис. 3-4. Объект COM может предоставлять несколько неизменных интерфейсов и обычно состоит из многих внутренних объектов
Каждый интерфейс COM предоставляет метод QueryInterface. С его помощью осуществляется навигация между интерфейсами COM и, таким образом, обеспечивается полиморфизм. На диаграме выше существуют указатели между всеми предоставляемыми интерфейсами; они необходимы для реализации QueryInterface. QueryInterface также действует как механизм проверки версий: если он возвращает конкретный интерфейс, то его функциональность обеспечена. Версии, которые синтаксически или семантически отличаются друг от друга, должны предоставляться через разные интерфейсы. Для различения каждый интерфейс получает глобальный уникальный идентификатор (GUID), который представляет собой 128-битное число, неповторимое в пространстве и времени. Объекты COM размещаются косвенно через фабрики. Объект COM, который реализован в виде DLL, или EXE, который регистрируется самостоятельно при запуске, называется объектом ActiveX.
COM решает проблему синтаксически хрупкого базового класса запретом на изменение интерфейсов, то есть, будучи однажды официально выпущен, интерфейс не может изменяться больше никогда. Это также подразумевает, что двоичная структура интерфейса (позиция методов в таблице методов) больше никогда не изменится. Если появляется необходимость расширить интерфейс, новая функциональность может быть предоставлена в виде нового, расширенного интерфейса. Если новый интерфейс является строгим надмножеством старого, он может считаться его подтипом. В этих целях COM поддерживает (одиночное) наследование интерфейсов в своих IDL-библиотеках и библиотеках типов.
Раннее мы обсудили интерфейсы как контракты. Это поможет уяснить, почему интерфейсы COM не могут изменяться: будучи однажды широко опубликованным, интерфейс нельзя никоим образом изменить без одностороннего разрыва контракта, который он представлял.
В отличие от обычной схемы нумерации версий, схема COM неизменяемых и уникально идентифицируемых интерфейсов делает возможным нескольким независимым сторонам выпускать новые версии интерфейса, без риска создать конфликт версий. Более того, это упрощает миграцию со старого ПО на новое; во время перехода сохраняется возможность поддержки как старых, так и новых интерфейсов одновременно.
Что касается управления памятью, COM использует подсчет сылок: каждый интерфейс COM содержит, в ополнение к методу QueryInterface, методы AddRef и Release. AddRef должен увеличивать счетчик ссылок, а Release — уменьшать его. Когда количество ссылок уменьшится с единицы до нуля, это будет означать, что исчезла последняя внешняя ссылка, и интерфейс может уничтожить себя, и, возможно, другие данные объекта, если у него был только один интерфейс.
Распределенный COM (Distributed COM, DCOM) является расширением COM, которое добавляет поддержку распределенных объектов, используя в качестве основы упрощенную реализацию DCE. В трактовке DCOM клиент и сервер симметричны в том, что клиент не знает о том, вызывает ли он прокси или реальный сервер, и сервер не знает, пришел ли к нему вызов от заглушки (stub) или от настоящего клиента.
COM также был перенесен на другие платформы, чем Window, например, на Mac OS и несколько направлений Unix. COM начинался как собственный стандарт Microsoft, но позднее Microsoft передала контроль над ним организации по стандартизации Open Group.
Подобно CORBA и в противоположность SOM, COM не поддерживает наследование реализации. Для такого решения имелась тонкая, но важная причина. Подобно неоднозначному или недоопределенному контракту, наследование реализации вынуждает программистов опираться на предположения, которые могут больше не выполняться в новой версии базового класса. Такая ситуация называется проблемой семантической хрупкости базового класса. Наследование реализации может полностью контролироваться, если доступен исходный код базового класса, то есть, если в качестве интерфейса используется сама реализация. Но это подобно перегруженному контракту, напечатанному на многих страницах мелким шрифтом, и точно также не позволяет в дальнейшем улучшать реализацию базового класса.
Microsoft справедливо аргументирует, что наследование реализации не приводит к проблемам внутри компонента, который является «белым ящиком» с точки зрения его разработчика, но его не следует использовать между компонентами. Использование наследования реализации между компонентами потребовало бы строгих правил во избежание проблем с семантикой базовых классов. К сожалению, эти правила все еще являются темой для исследований [Szypersky97]. Поэтому библиотеки классов для компонентного ПО, например, классы SOM OpenDoc, избегают наследования реализации, даже если их объектные модели ее поддерживают. Наследование интерфейсов, также называемое субтипизацией, не подвержено таким проблемам, так как не затрагивает никакие аспекты реализации. Эта тема будет детально обсуждаться в разделе 4.1.
Если вы услышите от кого-либо из IBM, что в SOM решена проблема хрупкости базового класса задолго до появления COM, знайте, что имеется в виду синтаксическая хрупкость, то есть, двоичная совместимость версий. С другой стороны, если вы услышите от кого-либо из Microsoft о проблеме хрупкости базового класса, то в данном случае имеется в виду семантическая хрупкость. Неправильное понимание этих моментов настолько стереотипно, что становится смешным.
SOM и COM являются примерами объектных моделей, независящих от языка. Объектная модель всегда является частью среды времени выполнения; но с таким же успехом она может быть разработана для поддержки одного конкретного языка. Это ведет к моноязыковым объектным моделям, например, Java. Моноязыковые объектные модели имеют несколько преимуществ; в частности, их IDL могут быть чистыми подмножествами языка, что более естественно и удобно при разработке ПО.
Sun Microsystems определила объектную модель для своей Java Virtual Machine (JVM). Java была разработана для поддержки компонентов, перемещаемых в Интернет. Поскольку уверенно судить о качестве большинства ПО в Интернет невозможно, наибольшую важность приобретает защита от плохо работающих или вредоносных компонентов (вирусов!). В этих целях Java обеспечивает безопасность типов, и строгое соблюдение правил безопасности гарантируется не столько компилятором, сколько загрузчиком классов JVM. Например, проводить неконтролирумые преобразования типов в Java-коде не позволяется. Эти правила исключают использование небезопасных языков, таких как C, C++ и даже оригинального Паскаля. Эти языки не могут быть откомпилированы в код JVM (в противном случае не было бы вообще никакой фундаментальной причины переходить от C++ к Java). Напротив, JVM-компиляторы для Smalltalk, Eiffel, Lisp, Component Pascal или версии Ada со сборкой мусора вполне возможны1).
Так как висячие ссылки делают Java небезопасной, JVM требует сборки мусора. Точный механизм, который для этого используется, оставлен на усмотрение реализации.
Java-код компилируется в байт-код Java, который можно рассматривать как набор инструкций для виртуального Java-процессора. JVM либо интерпретирует байт-код, либо осуществляет его прекомпиляцию в машинный код в момент загрузки или во время выполнения, используя так называемый Just-In-Time компилятор (JIT). Файлы классов полностью машинно-независимы, поскольку в отличие от обычных компонентов SOM или COM, чистый JVM-код машинно-независим. Каждый класс компилируется в свой собственный файл класса. Обычно в качестве простого репозитория интерфейсов и реализаций используется файловая система — как набор файлов классов.
Java определяет конкретный формат кодовых файлов, но оставляет открытым общее представление программы в памяти. Это в некотором роде противоположно COM: COM не так заботится о формате кодовых файлов, но определяет конкретное представление в памяти интерфейсов объектов и их таблицы методов. CORBA оставляет абстрактными представление как на диске, так и в памяти.
Проверка версий Java-кода проводится во время выполнения. Существование метода проверяется в момент его первого вызова. Это спорный подход, поскольку компонент может быть загружен и долго нормально работать, но внезапно — конечно же, тогда, когда вы меньше всего этого ждете — вызвать неожиданное исключение.
(Похожая проблема может возникнуть, когда вы получаете COM-интерфейс через QueryInterface, но один из его методов возвращает код ошибки, означающий, что он не реализован. Например, мы не видели пока что ни одного OLE-контейнера, которые реализует метод IOLEContainer.EnumObjects для перемещения по внедренным в контейнер отображениям.)
Java различает интерфейсы и классы. Интерфейсы могут находится в отношениях множественного наследования (субтипизации). Класс является реализацией одного или нескольких интерфейсов; классы могут находиться только в отношениях одиночного наследования (подклассификации). Контролируемые преобразования между типами делают возможной навигацию между различными интерфейсами, которые поддерживаются объектом. Семантически это эквивалентно тому механизму, который поддерживают CORBA и COM.
Различие между интерфейсами и классами должно минимизировать проблему семантической хрупкости базового класса: если субклассификация используется только внутри компонентов, а интерфейсы используются для наследования как внутри, так и между компонентами, то эта проблема, в основном, исчезает. К сожалению, разработчики библиотек Java не желают следовать никаким четким принципам, когда использовать интерфейсы и когда — классы.
Для распределенного взаимодействия Java-объектов существует Java RMI (Remote Method Invocation). Альтернативная реализация распределенности возможна через CORBA или COM, что требует наличия в Java шлюзов к этим объектным моделям. Языковые шлюзы определяют, например, как беззнаковые целые CORBA и COM преобразуются к знаковым целым Java (язык Java не поддерживает беззнаковые целые).
Совместимость и безопасность — совместимость и безопасность на двоичном уровне являются самыми главными отличиями JVM от SOM и COM. Безопасность имеет много аспектов, самый фундаментальный — целостность памяти. Около половины всех ошибок программирования связаны с памятью: недопустимая перезапись памяти, неосвобожденная неиспользуемая память (утечки памяти), или преждевременное освобождение памяти, которая еще используется (висячие ссылки). CORBA и SOM совсем не решают этот важный вопрос, что является их огромным недочетом. Без стандарта управления памятью на уровне объектной модели, способность компонентов надежно взаимодействовать ставится под угрозу. COM определяет механизм подсчета ссылок, который решает проблему по крайней мере для нецикличных структур данных. К сожалению, большинство интересных структур данных цикличны, и следовательно, COM выталкивает часть сложностей управления памятью на верхний уровень программного обеспечения. Подсчет ссылок не способен уберечь не только от утечек памяти, но и от более опасных висячих указателей. JVM предоставляет действительно автоматическую сборку мусора и другие механизмы безопасности.2)
Компонентный Паскаль — язык из одного семейства с Паскалем, Модулой-2 и Обероном. Он является компонентно-ориентированным аналогом этих языков. Его качества безопасности эквивалентны Java. Для взаимодействия с ПО третьих сторон и для написания драйверов устройств есть специальные библиотеки, которые помогают разрабатывать небезопасный код в контроллируемом стиле. Во многих отношениях объектная модель Компонентного Паскаля проще, чем у Java.
Специальная версия компилятора Direct-To-COM поддерживает COM, напрямую приводя записи Компонентного Паскаля к проверенным типам интерфейсов COM (включая проверки режимов параметров MIDL. Что более важно, этот специальный компилятор освобождает программиста от ручной работы с механизмом учета ссылок COM, то есть, добавляет к COM-объектам сборщик мусора. Поскольку компилятор лишь автоматизирует то, что в любом случае пришлось бы делать вручную, это не дает никаких накладных расходов.
| Аспект | CORBA | SOM | COM | Java | Component Pascal |
|---|---|---|---|---|---|
| создатель | OMG | IBM | Microsoft | Sun | Oberon microsystems |
| IDL | CORBA IDL | расш. CORBA IDL | расш. DCE IDL | подмнож. Java (1) | подмнож. CP(1) |
| метаклассы | нет | да | нет | нет | нет |
| указатели (2) | нет (3) | да | да | да | да |
| наследование реализации | нет | да | нет | да | да |
| репозиторий интерфейсов | да | да | библ. типов | да (4) | да (5) |
| двоич. стандарт памяти | нет | да | да | нет | нет |
| двоич. стандарт код. файлов | нет | нет (обыч. DLL) | нет (обыч. DLL) | да (переносимые DLL) | нет (обыч. DLL) |
| переносимые кодовые файлы | нет | нет | нет | да | нет |
| репозиторий реализаций | да | да | реестр | да (4) | да (6) |
| контроль версий | нет (7) | нет (7) | неизм. интерф. | да (8) | да (9) |
| соглашения вызовов | неопред. | обычные | обычные | специальные (10) | обычные + специальные |
| сист. типов во время выполн. | да (11) | да | да (12) | да (13) | да (14) |
| управление памятью | неопред. | неопред. (15) | счетчик ссылок | сборка мусора | сборка мусора |
| решение синтаксич. ПХБК | нет | нет | да | да | да |
| решение семантич. ПХБК | нет насл. реализации | не решена | нет наслед. реализации | интерфейсы/классы(16) | по соглашению (16) |
| распределенные объекты | да | DSOM | DCOM | Java RMI (17) | нет (18) |
(1) доступ к CORBA и COM возможен через через языковые преобразования «прямых» компиляторов, плюс библиотеки для взаимодействия
(2) могут ли указатели/ссылки языка программирования использоваться напрямую, например, для вызова методов или передачи параметров?
(3) нужно использовать вcпомогательные ссылочные объекты, которые снижают удобство и эффективность
(4) обычно прямое отображение файлов классов
(5) обычно прямое отображение символьных файлов
(6) обычно прямое отображение кодовых файлов
(7) существует минимальная поддержка, позволяющая клиенту проводить такую проверку (прагма-директивы, номера главной/вспомогательной версий)
(8) автоматическая проверка, когда элемент компонента первый раз используется
(9) автоматическая проверка каждого объекта при загрузке модуля
(10) обычные вызовы требуют для «склейки» классы-обертки; эффективность встроенных вызовов недостижима; нельзя создать DLL с обычными вызовами
(11) репозиторий интерфейсов, get_interface(), interfaceDef, is_a, describe_interface
(12) QueryInterface, IDispatch, IProvideClassInfo
(13) проверки типов (instanceof), приведения типов, интерфейс рефлексии Java
(14) проверки типов (IS), охрана типов, модуль Meta
(15) кроме Mac SOM, которая использует подсчет ссылок
(16) по соглашению, наследование реализаций используется только внутри компонентов (библиотеки Java непоследовательны в этом отношении)
(17) объект помечается как удаленный наследованием от интерфейса из специальной библиотеки
(18) в качестве соединительной объектной шины используется DCOM, через специальный компилятор Direct-To-COM
Таблица 3-5. Сравнение различных объектных моделей
(Прим. переводчика: в нескольких последующих абзацах будущее время заменено на прошедшее, с минимальными изменениями содержания. Прогнозы автора оказались достаточно точными.)
Какая объектная модель победила?
Очевидно, что никакая. COM и некоторые реализации CORBA сосуществуют довольно долго. Территории COM и CORBA связаны мостами. Это вызывает много проблем взаимодействия, но не более, чем работа одновременно с несколькими различными реализациями CORBA, или с несколькими языками программирования и одной реализацией CORBA.
Microsoft собиралась расширить COM поддержкой автоматической сборки мусора и обработки исключений3). Поскольку COM в основе своей языково-независима, Java-образные языки выигрывают от такой поддержки. С другой стороны, Sun ввела Java Native Interface (JNI), который использует структуру методов, подобную той, которая принята в COM. Похоже на то, что объектные модели сходятся в основном на COM и JVM, которые начинают в некоторой степени перекрываться. CORBA уходит на вторые роли как невидимый коммуникационный слой, который может, но не обязательно будет, использоваться двумя другими объектными моделями.
Мы поговорили только об основных объектных моделях, которые являются низкоуровневым «оборудованием» для межпрограммного взаимодействия. Однако, объектная война может быть решена в конце концов службами, построенными поверх объектных моделей. Вероятно, не службами для «мелкозернистых» объектов, такими как службы отношений или перманентности (relationship or persistence) CORBA, но службами, которые требуются для надежной совместной работы компонентов среднего размера. В настольных средах это составные документы, доступ к базам данных и сетевые службы. В корпоративных средах это службы безопасности, асинхронные службы групповых сообщений, службы транзакций и службы директорий. CORBA стандартизировала эти службы, но реальное ПО для них появилось намного позже. За несколько лет, которые CORBA наслаждалась своим успехом, Microsoft нагнала ее, и Java тоже не осталась далеко позади.
Главный вопрос относительно CORBA, которая разработана комитетом из сотни компаний, — не произойдет ли с ней той же проблемы, что и с Unix, то есть, не останется ли она вечным «почти стандартом». Кому будет больше доверять заказчик: консорциуму со смешанным сотрудничеством, или Microsoft с ее иногда монополистической позицией?
Сегодня (сентябрь 1997) кажется более вероятным, что CORBA (например, IBM ComponentBroker, который заменит неудачный DSOM) в течение некоторого времени будет оставаться важной инфраструктурой для связи между корпоративными приложениями. Протокол Internet Inter-ORB (IIOP) все еще может стать предпочтительным протоколом коммуникации между распределенными объектами Java (через Java RMI). Все составляющие CORBA, включая IDL, языковые связи, и в частности, объектные службы потерпели крупное поражение на (компонентном) рынке. Нереально все еще надеяться, что CORBA будет играть роль эффективной (компонентной) объектной модели с большим рынком двоично-совместимых «коробочных» компонентов.
Microsoft победила в настольных средах и продвигается в корпоративные благодаря Windows NT, DCOM, Интернет-службам и своей службе транзакций. Microsoft также охватила и Java, тесно интегрировав с COM ее систему времени выполнения.
Возможно, что со временем разработчики осознают, что такие общие объектные модели, как SOM или OM необходимы в качестве «базовых объектных шин» («backplane object buses»), но их прямое использование часто слишком дорого обходится. Каркасы (frameworks) могут предоставить путь к простым и более эффективным объектным моделям. Эти легковесные и экономически выгодные объектные модели будут привязаны к языку и могут напрямую не поддерживать распределенность. Есть пример такой разработки: существуют индустриальные стандарты на аппаратные базовые шины, например, Motorola VME bus, которые дороги, сложны и относительно медленны. Но сегодня там же существуют высокоуровневые, дешевые VME boards, которые относительно обобщены (каркасы) и предоставляют локальную, простую, быструю, недорогую и расширяемую шину (Inustry Pac bus), для которой на рынке существует несколько сотен расширений. Можно ожидать, что такие разработки появятся и в мире программного обеспечения. Заметим, что когда реализована базовая объектная модель, то намного дешевле и менее рискованно выводить на рынок одну или несколько специализированных вторичных объектных моделей, поскольку для них не требуется универсальная поддержка. При более экзотических потребностях вы всегда сможете отступить к базовой объектной модели.
Альтернативным может стать появление объектной модели, независящей от языка, но достаточно легковесной, чтобы позволить эффективную разработку без горомоздких отдельных IDL и неэффективного межпроцессного взаимодействия. Microsoft пытается это сделать в новом поколении COM, названном COM+. COM+ — это внутрипроцессная объектная модель; она все еще использует DCOM для межпроцессных и межмашинных взаимодействий. По сравнению с COM она имеет более абстрактное определение того, как объекты и классы представляются в памяти (и на диске). Ее можно рассматривать как более общую архитектуру, чем виртуальная машина Java, поскольку она поддерживает широкий спектр языков программирования и форматов кодовых файлов. В противоположность COM, она предоставляет систематический путь для расширения собсвенной инфраструктуры времени выполнения сторонними компонентами (например, отладчиками, профилировщиками и т.п.) стандартным образом. Она устраняет проблему учета ссылок в COM введением полноценной сборки мусора. Ее типы полностью поддерживают интерфейсы и классы Java (к сожалению, введено наследование реализации и доступ к полям между компонентами…). Широкое использование метаданных делает COM+ очень динамичной средой, хорошо подходящей для Java, Component Pascal и языков сценариев (как компилируемых, так и интерпретируемых), и снимает необходимость реализовывать громоздкие и излишние интерфейсы IDispatch в OLE Automation. В COM+ планируется ввести многие стандартные службы, включая безопасность и транзакции. Они аналогичны объектным службам CORBA, но лучше сфокусированы и интегрированы. Если Microsoft не допустит крупных ошибок, возможность смешивать COM и COM+ — компоненты сделают переход безболезненным и фактически гарантируют успех нового стандарта. Технические преимущества являются залогом этого. Новая объектная модель:
- гибкая, насколько возможно, но настолько конкретная, чтобы обеспечить двоичную совместимость для «коробочных» компонентов (хотя: предоставленная свобода на представление интерфейсов объектов в памяти добавляет дополнительную сложность, и во что это выльется в плане эффективности, еще надо посмотреть)
- это архитектура виртуальной машины для динамических языков, подобных Java (без необходимости любых в IDL или кода межязыковых преобразований), в том числе сценарных языков
- предоставляет стандартную инфраструктуру для подключения низкоуровневого инструментария, разработанного третьей стороной
- поддерживает сборку мусора, которая устраняет небезопасное и громоздкое ручное управление жизненным циклом объектов
- поддерживает эффективную внутрипроцессную совместную работу различных компонентов безопасным образом.
Можно надеятся, что COM+ поможет преодолеть неудачное понятие процесса Unix, которое стало столь продолжительным препятствием на пути к практически пригодному компонентному ПО, и расчистить место для операционных систем с единым адресным пространством, которые обеспечивают защиту за счет безопасных языков программирования и, возможно, через новые схемы аппаратной защиты. Тем временем, будет заманчиво использовать возможности нового COM+ таким образом, который не ведет к эксплуатационным и административным кошмарам, вызванным проблемами семантически хрупкого базового класса и управления версиями.
3.5 Стандарты составных документов
Какого рода службы должна предоставлять программная инфраструктура для составных документов? В основном это разделение ресурсов. Отображения в составных документах делят экранное пространство, файлы, устройства ввода и т.п. Должны существовать правила, по которым отображения должны сотрудничать при использовании общих ресурсов. Без таких правил отображения могут рисовать за пределами своей области, могут портить содержимое других отображений или файлов, и так далее.
Правила могут быть собраны в контракте, то есть, приведены к интерфейсам. Для таких интерфейсов наиболее успешный стандарт пока — Microsoft OLE (изначально — аббревиатура от Object Linking end Embedding). OLE определена как архитектура для визуального представления составных документов. Она дополнена архитектурами для хранения OLE-объектов (структурированные хранилища) и сценариями для OLE-объектов (OLE Automation). Эти архитектуры включены в большое количество интерфейсов COM, например, для перманентного хранения отображений, для перетаскивания между ними, для редактирования на месте внедрения, и для многого другого. В основном по историческим причинам OLE делает сильные различия между отображениями разного рода — документными объектами и элементами управления, между документными контейнерами и контейнерами элементов управления. Также по историческим причинам делается различие между нормальной объектной моделью (то есть, COM) и специальной объектной моделью для Автоматизации, то есть, для сборки компонентов. Visual Basic является типичным языком сценариев, который использует Автоматизацию.
К сожалению, такие различия перегружают разработчика необязательными решениями и добавляют значительную сложность. Например, Microsoft рекомендует предоставлять каждый интерфейс как нормальном COM-варианте, так и для Автоматизации. Интерфейс COM эффективен и мощен, но может быть небезопасен, в то время как интерфейс Автоматизации безопасен, но малоэффективен (и не полностью поддерживает некоторые типы параметров). Java показала, что моноязыковая объектная модель может сочетать в себе достаточную мощь и безопасность; а Компонентный Паскаль показал, что это может не приводить ни к каким потерям в быстродействии.
OLE изначально разрабатывался, чтобы позволить взаимодействовать различным традиционным приложениям, например, Microsoft Word и Microsoft Excel. В этих целях большинство OLE-приложений являются полноценными EXE. Легковесные компоненты, реализованные в виде DLL, появились позже, в виде элементов управления ActiveX. Элементы управления разделяют одно и то же адресное пространство.
Единственная причина успеха OLE в том, что оно облегчило переход к компонентному ПО с поддержкой и традиционных больших приложений, и легковесных компонентов, но с другой стороны, излишняя поддержка EXE-файлов ведет к значительному увеличению сложности.
OpenDoc был разработан Component Integration Labs (CILabs) в качестве альтернативы OLE. CILabs была консорциумом, состоящим из Apple, IBM и сотен других компаний. OpenDoc был разработан для поддержки настоящих компонентов. Поэтому отображения OpenDoc, так называемые Live Objects, не приходится разрабатывать одновременно как компоненты и полноценные приложения. Другое отличие от OLE состоит в том, что OpenDoc изначально был разработан как кросс-платформенная архитектура. Подобно OLE OpenDoc предоставляет интерфейс автоматизации в дополнение к объектной модели SOM (OSA, Open Scripting Architecture), который так же излишен и громоздок, как и его аналог в OLE. Положительным аспектом является отсутствие различий между документными объектами и элементами управления.
OpenDoc — это каркас, состоящий из классов SOM. Он кое-где использует наследование реализации, и нигде — множественное наследование, и следовательно, почти не страдает от проблемы семантической хрупкости базового класса. OpenDoc предоставляет некоторые службы, которые в OLE предоставляются на более низком уровне, фактически уже в объектной модели COM. В частности, механизм расширения, который позволяет позволяет динамически получать расширенные интерфейсы отображения (подобно QueryInterface), и схема подсчета ссылок для управления памятью.
Документ OpenDoc открывает свое собственное адресное пространство, которое делится всеми OpenDoc-отображениями, которые находятся в этом документе. Реализация отображений может находиться в другом адресном пространстве, для этого используется DCOM. Подобно OLE, работа с адресными пространствами в OpenDoc является компромисом между размещением всего в одном адресном пространстве (очень гибко, удобно, эффективно; но очень небезопасно) и размещением каждого компонента в его собственном адресном пространстве (безопасно, но очень неудобно и громоздко). Более удовлетворительного компромисса можно достичь лишь на лучшей аппаратной защите (маловероятно, что она появится), или с переходом на безопасные языки программирования. Дополнительно об этом скажем далее.
OpenDoc кажется проще и меньше перегруженным заботой об обратной совместимости, чем OLE, и это должно компенсировать некоторые недостатки лежащей в основе объектной модели. В частности, OpenDoc предоставляет более ясное толокование того, что есть отображение, и элементы управления и контейнеры являются просто специальными отображениями. OLE не имеет ясного представления о том, что представляет из себя контейнер; различные контейнеры могут поддерживать различные подмножества интерфейсов контейнеров. Это может привести к опасной хрупкости, так как объекты OLE приходится тестировать во многих контейнерах, но это не гарантирует, что они будут работать в других. Было бы очень полезным, если бы Microsoft опубликовала ясный и жесткий контракт для контейнеров.
Разнообразные возможности контейнеров ActiveX подчеркивают главную опасность COM (и Java) в плане стиля программирования: если слишком многие интерфейсы службы необязательны, становится чрезвычайно трудно гарантировать работоспособность клиента при всех обстоятельствах, поскольку ничего нельзя считать самим собой разумеющимся. Этот эффект имеет дурную славу среди программистов, которые используют библиотеку Microsoft ODBC (Open Database Connectivity), где абсолютно любая процедура может дать сбой, поскольку ее реализация необязательна.
Та же головная боль характерна и для распределенных объектов, когда отключение сервера или сети может привести к сбою при вызове любого метода. Транзакции являются единственным практичным решением для этой проблемы, но их рассмотрение выходит за рамки данной книги, и в любом случае не важно для локально взаимодействующих компонентов.
Чтобы помочь обеспечить высокий уровень согласованности и качества компонентов, CILabs предоставляет наборы и службы для тестирования частей OpenDoc. Это было похвальной инициативой, которая должна была стать большим подспорьем для разработчиков компонентов составных документов, в частности, контейнеров, и покупателей, следящих за качеством компонентов. Однако OpenDoc никогда не имел критической массы на рынке. Задержки в появлении версии для Windows, подвижки в обязательствах компаний — членов CILabs и недостаточное понимание руководством Apple природы компонентного ПО в конце концов обусловили провал OpenDoc. Он всегда рассматривался как периферийная технология, а не как нечто фундаметальное для будущего информатики.
Несмотря на неудачу OpenDoc, некоторые из его идей еще могут появиться в следующих версиях Java Beans. Java Beans — это каркас, который позволяет реализовывать переносимые элементы управления или оборачивать традиционные в классы Java. Java Beans не является полноценной архитектурой для составных документов, там нет общности, необходимой для разработки развитых контейнеров. Более того, bean-контейнеры неизменяемы, то есть, они не могут изменять размер, добавлять или удалять внедренные beans. Это отражает неизменную природу HTML Web-страниц.
Сегодня Java Beans всего лишь слой между Java-компонентами и полноценными архитектурами составных документов, такими как OLE или OpenDoc. Наиболее вероятно в будущем, что Java Beans будут расширены до отдельной архитектуры составных документов.
Java Beans продемонстрировали интересный конструктивный трюк. Было рекомендованы bean-клиентам не использовать проверки типов Java для beans; вместо этого bean предоставляет методы, подобные QueryInterface в COM. Тот факт, что и Java Beans, и OpenDoc вводили QueryInterface-подобный механизм в дополнение к своим системам типов, не говорит об их особой «мудрости».
BlackBox Component Framework, который мы обсудим более детально далее, во многих аспектах похож на OpenDoc, но более легковесный. В противоположность всем другим архитектурам, он предоставляет расширенную поддержку контейнеров — наиболее сложных типов отображений. Он скрывает различия между пользовательскими интерфейсами OLE и OpenDoc. В BCF у контейнеров есть различные режимы, поэтому каждый контейнер становится мощным визуальным редактором.
| Аспект | OLE | OpenDoc | Java Beans | BCF |
|---|---|---|---|---|
| Название компонента | ActiveX Object | Live Object | Bean | BlackBox Component |
| Автор стандарта | Microsoft | Apple | Sun Microsystems | Oberon Microsystems |
| Владелец стандарта | Open Group | CILabs ┼ | Sun Microsystems | Oberon Microsystems |
| Объектная модель | COM | SOM | Java | Component Pascal |
| Автоматизация | Automation | OSA | Java | Component Pascal |
| Составные файлы | Structured Storage | Bento | да 1) | да 2) |
| Разные форматы файлов на каждое отображение 3) | нет | нет | нет | нет |
| Пользователь управляет выбором редактора | да 4) | да 4) | нет 5) | нет 5) |
| Многоуровневый undo/redo | нет | да | нет | да 6) |
| Разделяемые меню | да | да | планируется | да |
| Обмен/преобразование данных | да | да | планируется | да |
| Вывод графики | Windows GDI 7) | напр., QuickDraw 7) | Java AWT | BCF |
| Свойства | да | нет | да | да |
| Перекрывающиеся отображения | да | да | нет | да |
| Непрямоугольные отображения | да | да | нет | нет |
| Embeddable in editor | да | да | нет 8) | да |
| Итераторы в контейнерах | в принципе 9) | нет | нет 10) | да |
| Container user interface | OLE | OpenDoc | не доступен 10) | OLE / OpenDoc 11) |
| Режимы для контейнеров | нет | нет | ограниченно 12) | да 13) |
1) Есть языковая и бибилотечная поддержка (метапрограммирование/рефлексия) для интернализации/экстернализации beans
2) Модуль Stores поддерживает интернализацию/экстернализацию произвольных графов, включая трансляцию указателей
3) В том смысле, что объект может поддерживать различные форматы файлов и, возможно, преобразования между ними
4) Есть инструменты, которые позволяют конечному пользователю задавать предпочитаемый редактор для каждого типа файлов
5) Тип объекта хранится вместе с его данными (автоматизировано с помощью средств метапрограммирования)
6) Несколько отменяемых команд могут быть собраны в сценарий, который отменяется как единое целое (вложенная отмена)
7) OLE и OpenDoc опираются на графические библиотеки операционной системы
8) Во время использования («run-time») bean-контейнер не может редактироваться (то есть, передвигаться, менять размер и т.п.)
9) Поддержка итераторов для контейнеров необязательна и на практике не реализована нигде
10) Bean не поддерживает контейнеров
11) Модуль Containers поддерживает общие контейнеры, абстрагируюясь от деталей пользовательского интерфейса OLE и OpenDoc
12) Делается различие только между «временем разработки» и «временем выполнения». Во «время разработки» beans можно перемещать и изменять их размеры
13) Режимы Правки/Разметки/Просмотра/Маски делают излишними отдельный визуальный дизайнер форм или редактор документации
Таблица 3-6. Сравнение различных архитектур составных документов
В предыдущем разделе мы упомянули, что имеет смысл дополнять универсальную базовую объектную модель более специализированными легковесными объектными моделями. Это подход можно наблюдать на примере Java. Java Beans — это каркас, который можно использовать как мост между объектной моделью JVM и базовыми объектными моделями и составными документами, в частности, COM/OLE. BCF следует похожей стратегии в отношении компонентов Компонентного Паскаля, но предоставляет гораздо более развитый каркас и среду по сравнению с Java Beans.
3.7 Стандарты на проблемно-ориентированные интерфейсы
Стандарты на объектные модели и составные документы необходимы, но никоим образом не достаточны для раскрытия потенциала рынка компонентного ПО. Для этого не менее нужны вертикальные, то есть, более специализированные и проблемно-ориентированные стандарты. Компоненты, ориентированные на разные области, не могут взаимодействовать, даже если они используют одну и ту же объектную модель. Например, не имеет смысла внедрять сетевой COM-драйвер в OLE-документ, даже если OLE также базируется на COM. Просто такие области слишком различны. Чтобы интеграция имела смысл, должна существовать общая почва, некоторый общий контекст. Этот контекст описывается в интерфейсе. Запомним, что определение компонента подразумевает, что все зависимости его контекста должны быть заданы явно в его интерфейсе.
Можно ожидать, что со временем будет разрабатываться все больше специализированных стандартов для таких областей, как финансовые службы, Интернет-коммуникации, работа с базами данных, и так далее. Сегодня мы находимся только в начале этого процесса, ведущего ко все более и более специализированным интерфейсам.
Но первый пример уже есть. Это группа компаний, которая определила OLE для Управления Процессами (Process Control, OPC); Apple, которая определила интерфейсы для Internet OpenDoc-отображений, ее Cyberlog — коллекция отображений, первая реализация этих интерфейсов; Java Database Connectivity (JDBC), которая является стандартным интерфейсом для компонентов Java, которым нужен доступ к реляционным базам данных; Commerce API — это Java API для секретных финансовых транзакций через Web; OLE для Retail Point-of-Sales (OPOS) управляет такими периферийными устройствами, как сканер штрих-кодов; Retail Application Framework Technology (RAFT) поддерживает трехзвенные приложения; и так далее.
Мы думаем, что некоторые из этих инициатив будут успешными, другие потерпят провал (все OpenDoc уже потерпели). Создание стандартных каркасов для «бизнес-объектов» — это очень заманчивое технически, политически и финансово предприятие. Как только отраслевой стандарт достигнет критической массы поддержки, экономия и выбор, который он предоставляет, уже не смогут быть биты никаким самостоятельным подходом.
Возможно, проблемно-ориентированные стандарты в основном будут определяться организациями пользователей, а не производителей, поскольку для этого требуется больше прикладных знаний, чем обычно имеется у производителя. Сегодня рынок ведут производители, но завтра рынок скорее всего будут вести заказчики.
Самое интересное в компонентном интерфейсе то, что он открывает потенциальный новый рынок. Он создает поле борьбы, на котором производители компонентов могут и должны конкурировать друг с другом. Будут привлекаться новые конкуренты; старые компании могут потерять свое преобладание. Временами создание хорошего стандарта на интерфейс критично. Долгий процесс стандартизации может привести к стандарту, который устарел к моменту своего создания. Поспешная стандартизация может привести к разработке низкого качества, которую придется пересматривать или заменять, теряя много времени и денег. Но нет иного пути кроме какой-либо стандартизации, поскольку без нее не будет рынка компонентов.